
Foreword: Before we begin, I have to say that you gotta trust me. I’m a normal sports fan and don’t overanalyze the heck out of a goal like this. Honestly, I’m not even sure if I should be writing this :)
Trust me, my first reaction was: WOW! What a goal!
When I looked at the 12 second mark in the above clip, I understood how this goal was scored (like every other armchair football analyst).
For those not football familiar, here’s what happens: Marquinhos blocks the initial shot attempt. Then, if you look closer 0:12 onwards you see Marquinhos’ initial momentum makes him rock back by a few inches giving Luis Díaz an opening to cut right and create a new shooting opportunity.
TLDR;
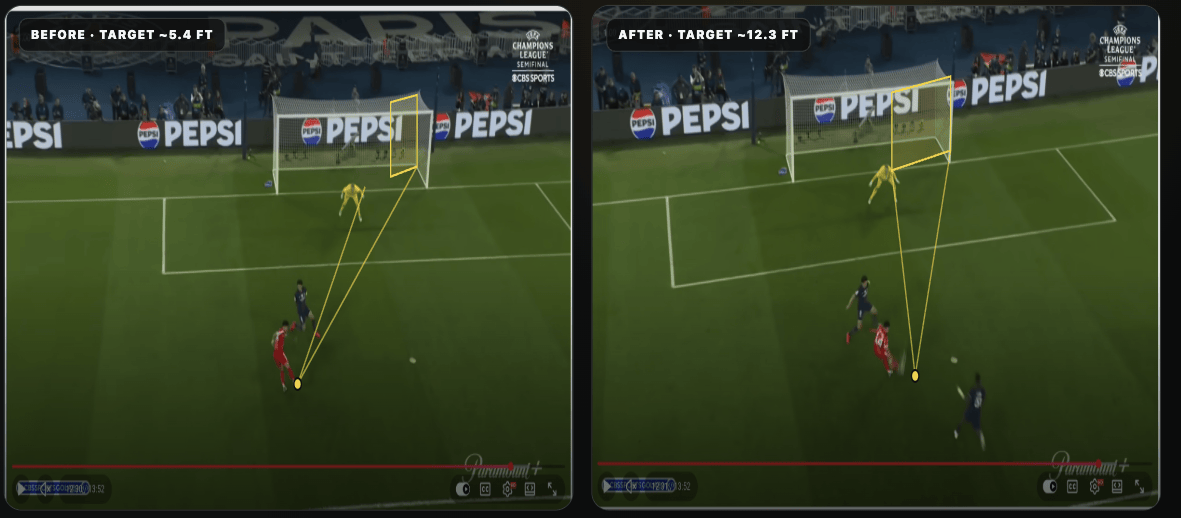
Here is the final result of how the goal was scored. Marquinhos rocks back ~0.6 ft, Luis Díaz cuts right ~8.9 ft resulting in the shot window opening up from ~5.5ft/8.6° to ~7.5ft/22.0°.
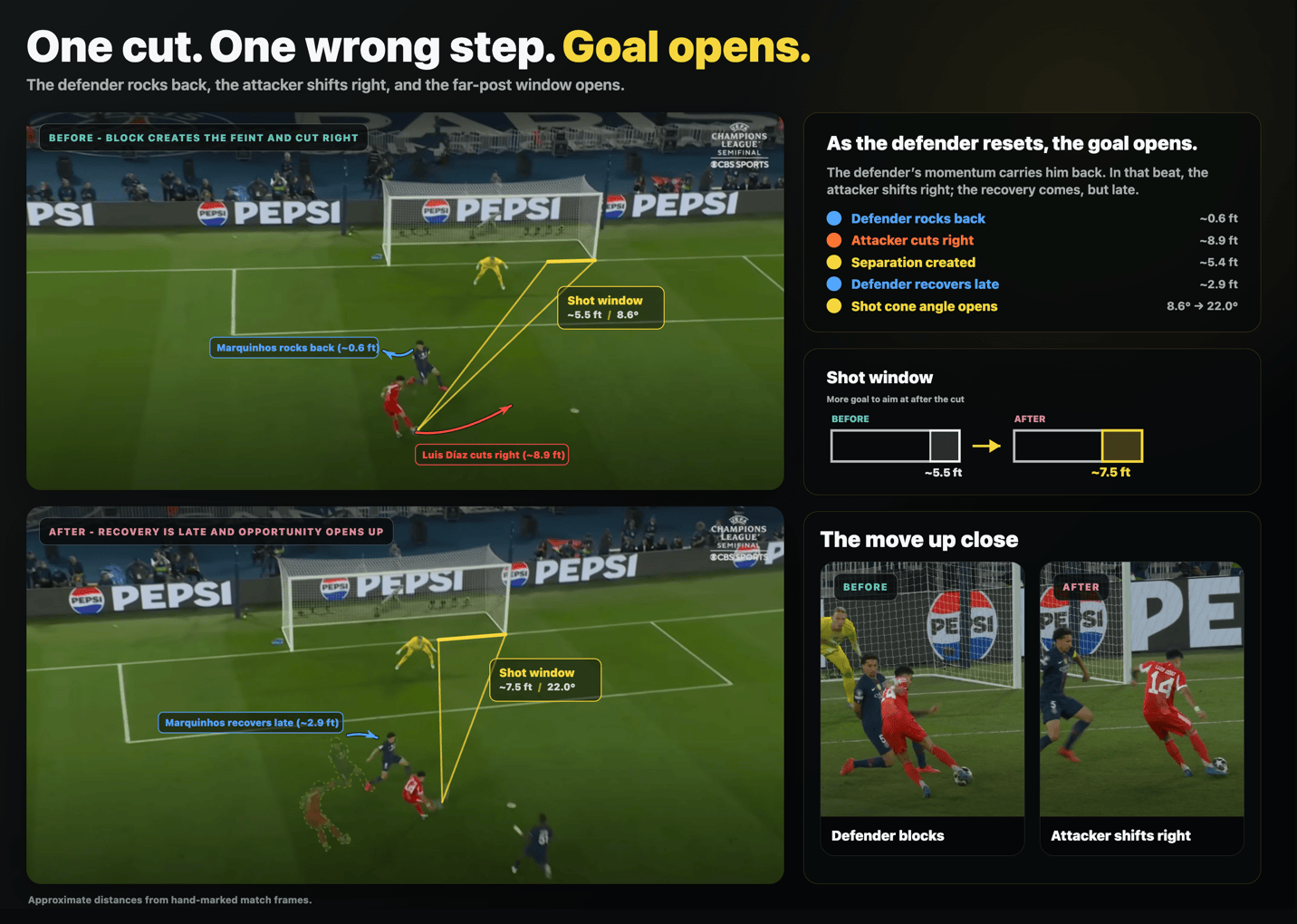
The part I keep thinking about is this: if I had let Codex fully guide the project, I would have ended up with a confident but wrong result. My football intuition caught things that Codex did not know to care about. The full story of how we got there is below.
The Long Version
For everyone else continuing on this ride, let’s talk about the rest of the story.
Can Codex solve this?

I gave Codex the screenshots of the play and described what I wanted. It thought other angles might help, so I pulled YouTube screenshots from a few alternate camera angles seen below.
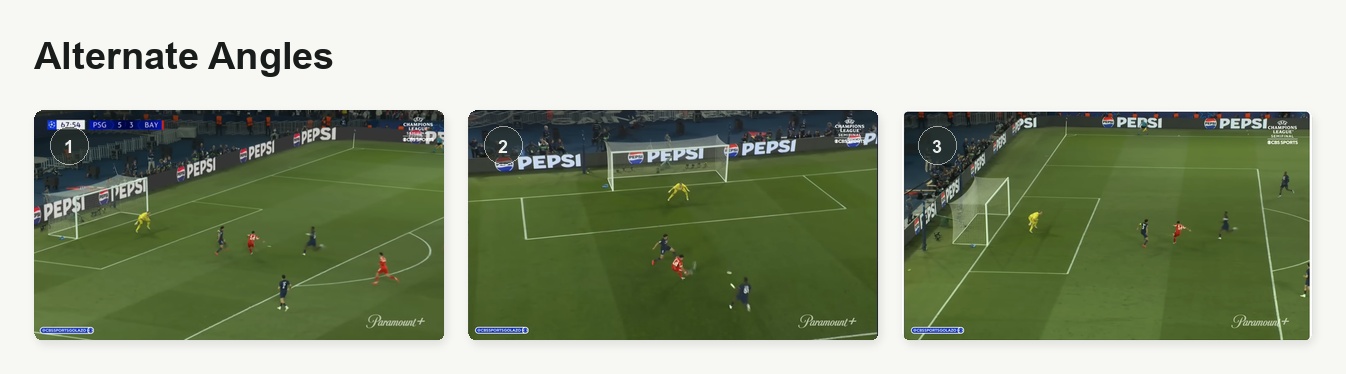
After a bit of back and forth, I decided that the following two frames best represented the change in distances we wanted to calculate (player movement, goal window) so I asked Codex to use these as the primary angle and other angles for validation.


Codex did what AI tools are very good at: it turned a fuzzy idea into a working direction. It suggested ways to measure distances, picked a Python image-processing stack, started detecting points, and generated annotated outputs. The first version looked convincing which I later found out was a problem.
The problem Codex created
I do not know much about computer vision, but I do know football. In the first attempt, Codex claimed that the “goal window became 2.3x wider” which did not pass the smell test for me. I manually compared the open goal window to the right of the goalkeeper in pixels and it definitely didn’t seem like the new window was 2.3x wider.
Out of curiosity, I asked Codex to “show its work” by “visualizing” how it came up with the distance calculations for my review. As I looked at the following annotated images, I quickly found out how off the calculations were. Codex tried to find goal posts, player positions, field lines, and distances but each measurement looked erroneous.
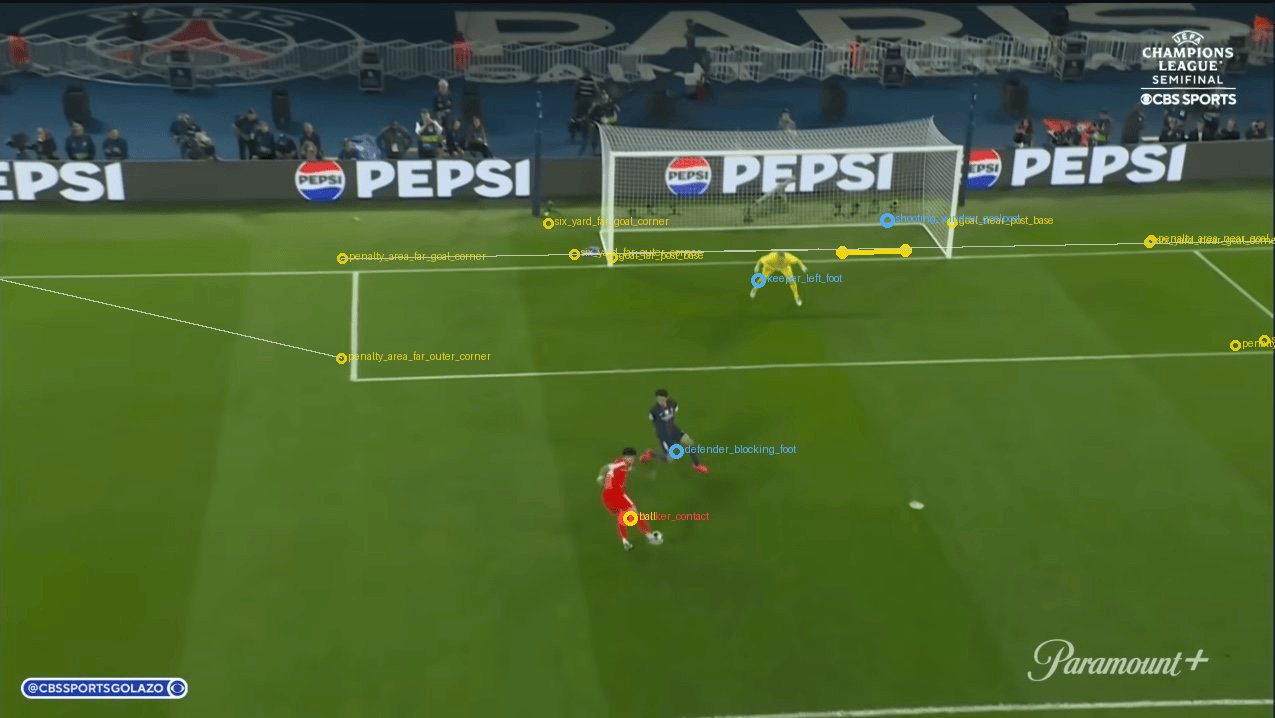
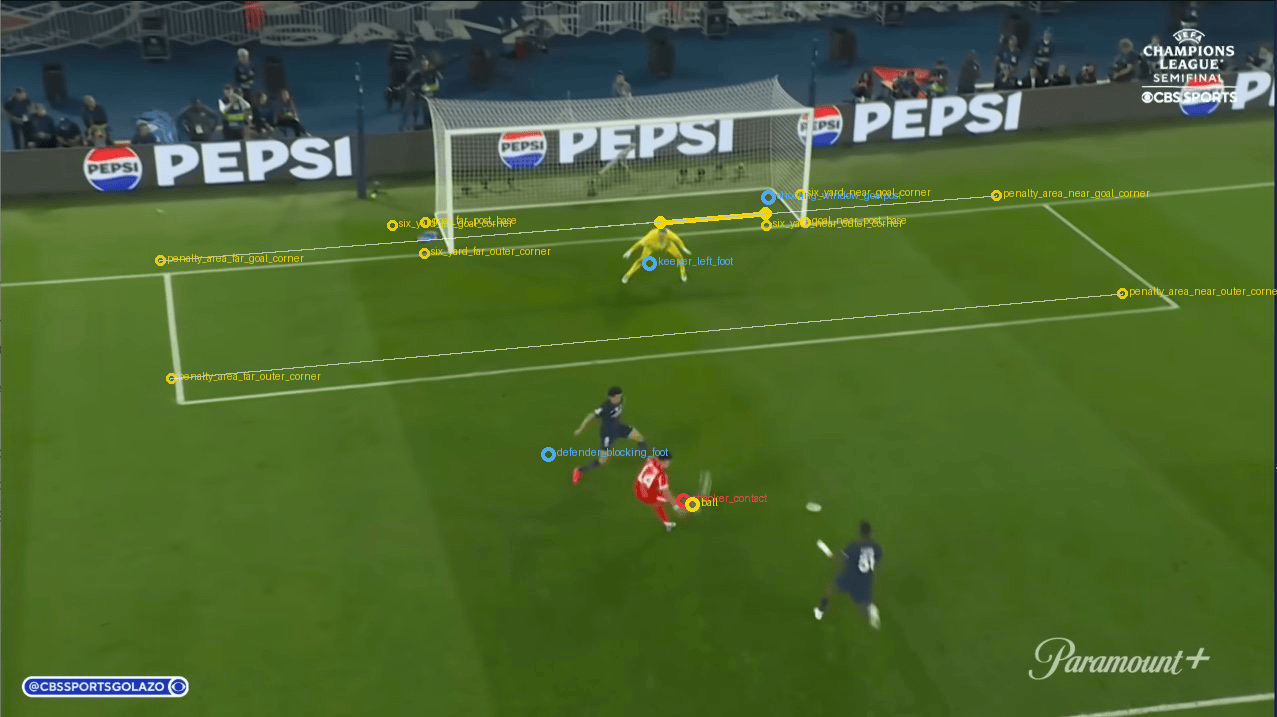
Some points were not exactly on the bottom of the goal posts. Some foot markers were close, but not close enough. The shot cone angle points were not in the expected places. This was a problem because if the goal post marker was five pixels off, or the player foot marker was placed on a shadow instead of the boot, the final number inherited that error.
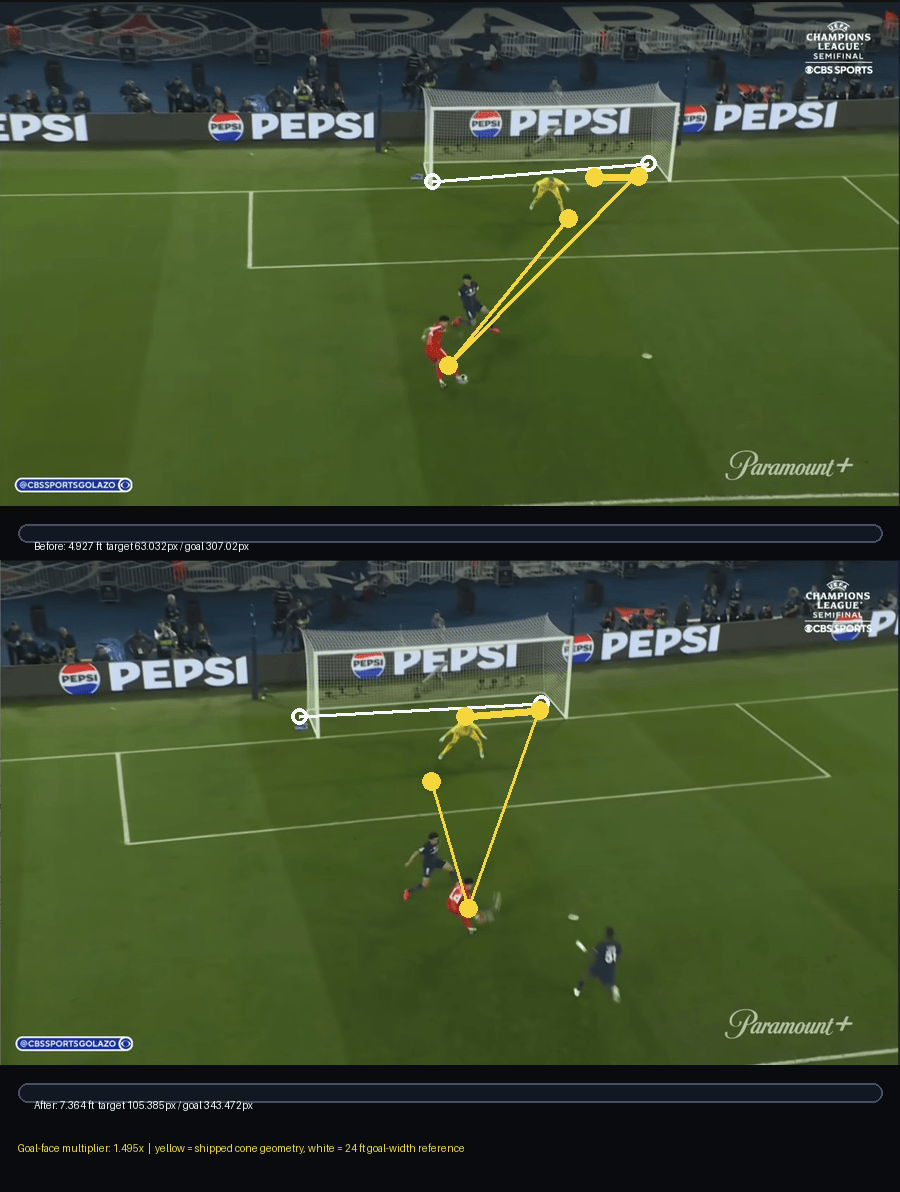

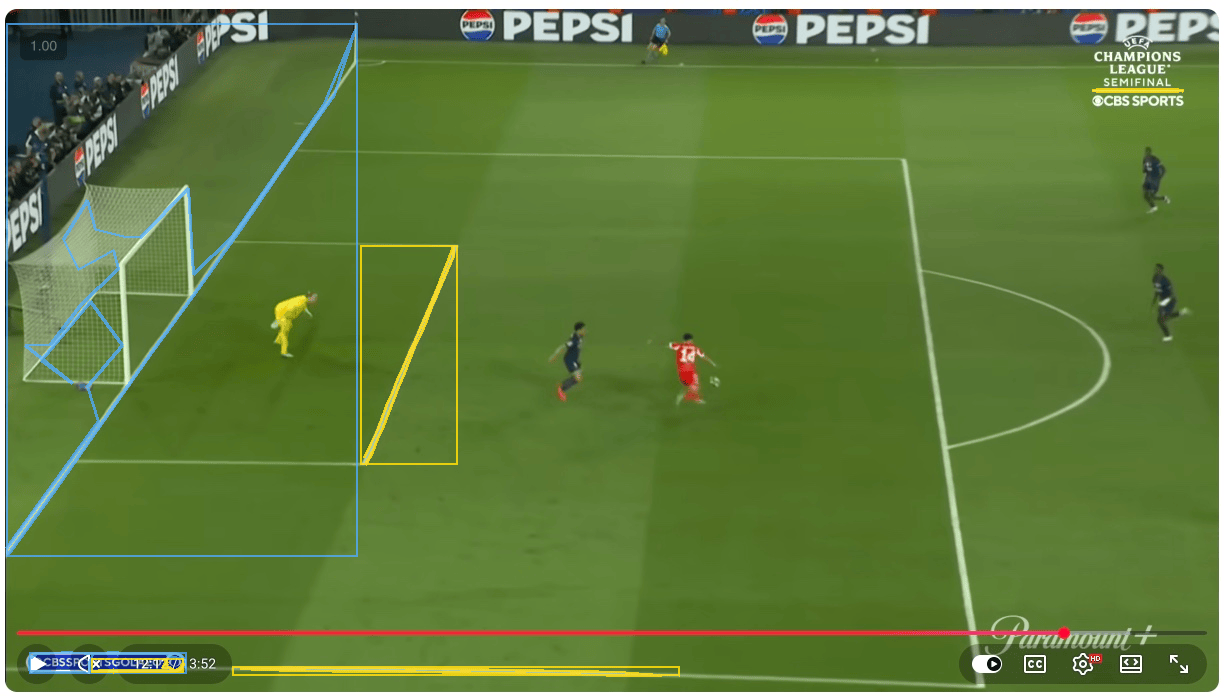

What I discovered was that agents can spend a lot of time “working” but it doesn’t reduce the hallucination tendencies.
Learning 1: Human domain expertise still matters
I asked Codex whether using the known football dimensions would simplify the measurement problem. Specifically, a regulation goal is 24 feet wide, 8 feet high. Similarly, the six-yard box, penalty area and penalty mark also have known dimensions. If the broadcast frame showed the goal mouth clearly, maybe we could use the known goal width to calibrate the shot window. Codex agreed that these would be “very useful” but I was left wondering why it had not suggested these originally.
Learning: The first insight came from me and not AI. I used my domain expertise to think through the known knowns to calculate the unknowns.
Learning 2: Human-in-the-loop still matters
After repeatedly prompting Codex again and again various versions of “Figure out better ways to detect objects more accurately” I had an epiphany. Why was I building a fully automated pipeline? Why couldn’t I provide “human judgement” to make the detection better?
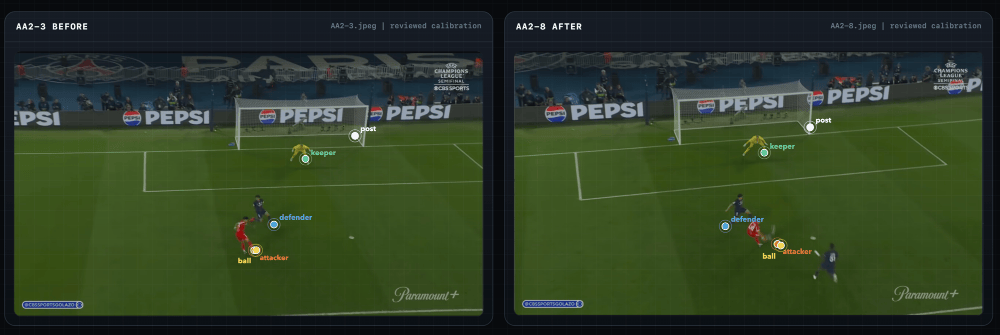
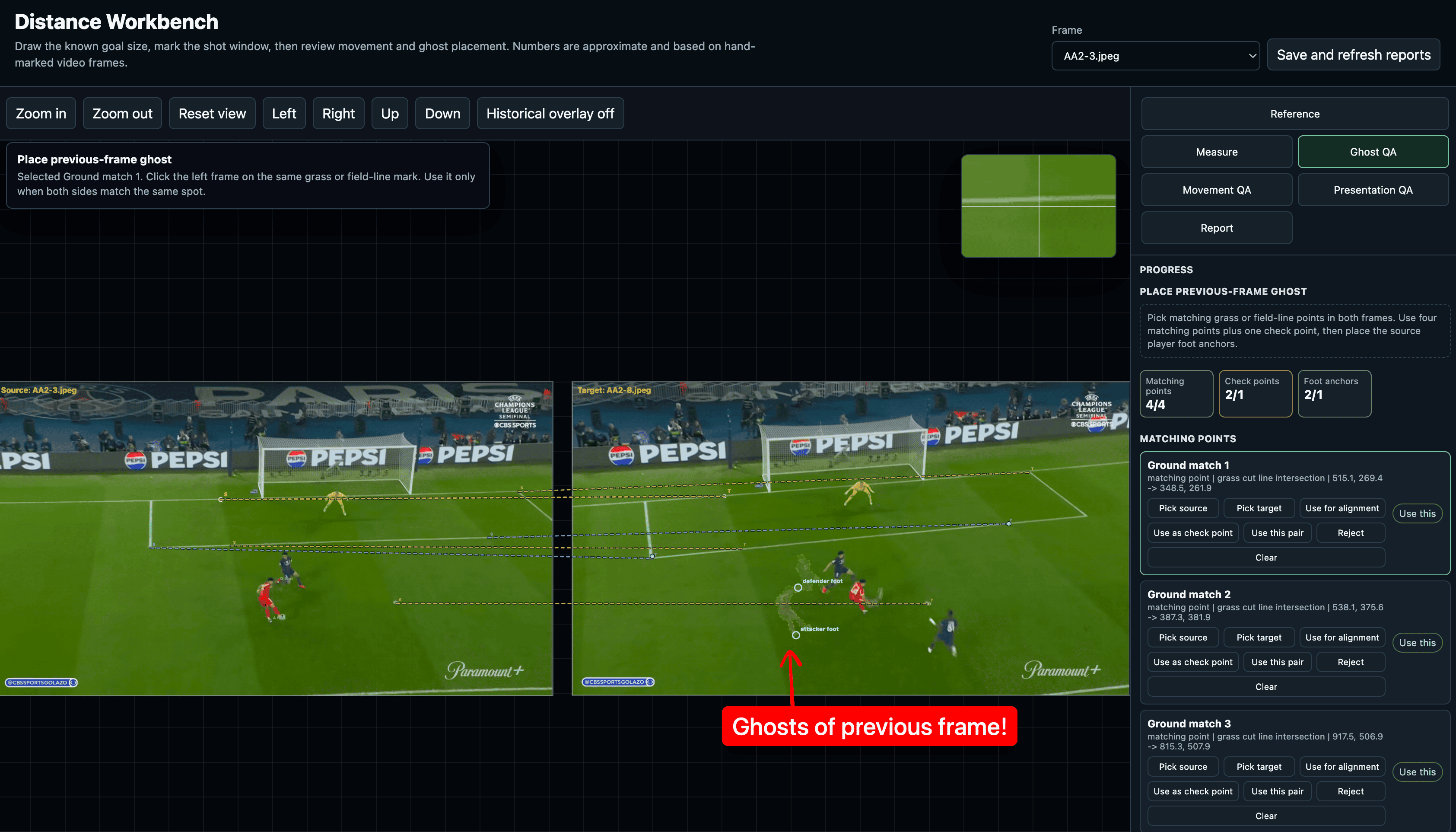
The automated pipeline kept placing the left goal post marker a few pixels inside the post rather than at the base. It was a small error that compounded through every downstream calculation. I figured if I could just click where I knew the base was, we could skip the guesswork entirely. So, I asked Codex if I could mark the important points and objects in the images used for calculations.
Codex built a manual distance workbench using HTML/CSS where I could load the frame, zoom in, place small points, drag endpoints, mark things as approved, and save the review data. Instead of treating automatic detections as truth, the system started treating my marks as the source of truth.
That helped as it turned the problem from “guess real-world distances from pixels” into something more grounded:
- Mark the inside width of the goal.
- Mark the open part of the goal.
- Compare the two.
- Convert the ratio into feet.
Here’s what that looked like in the workbench.
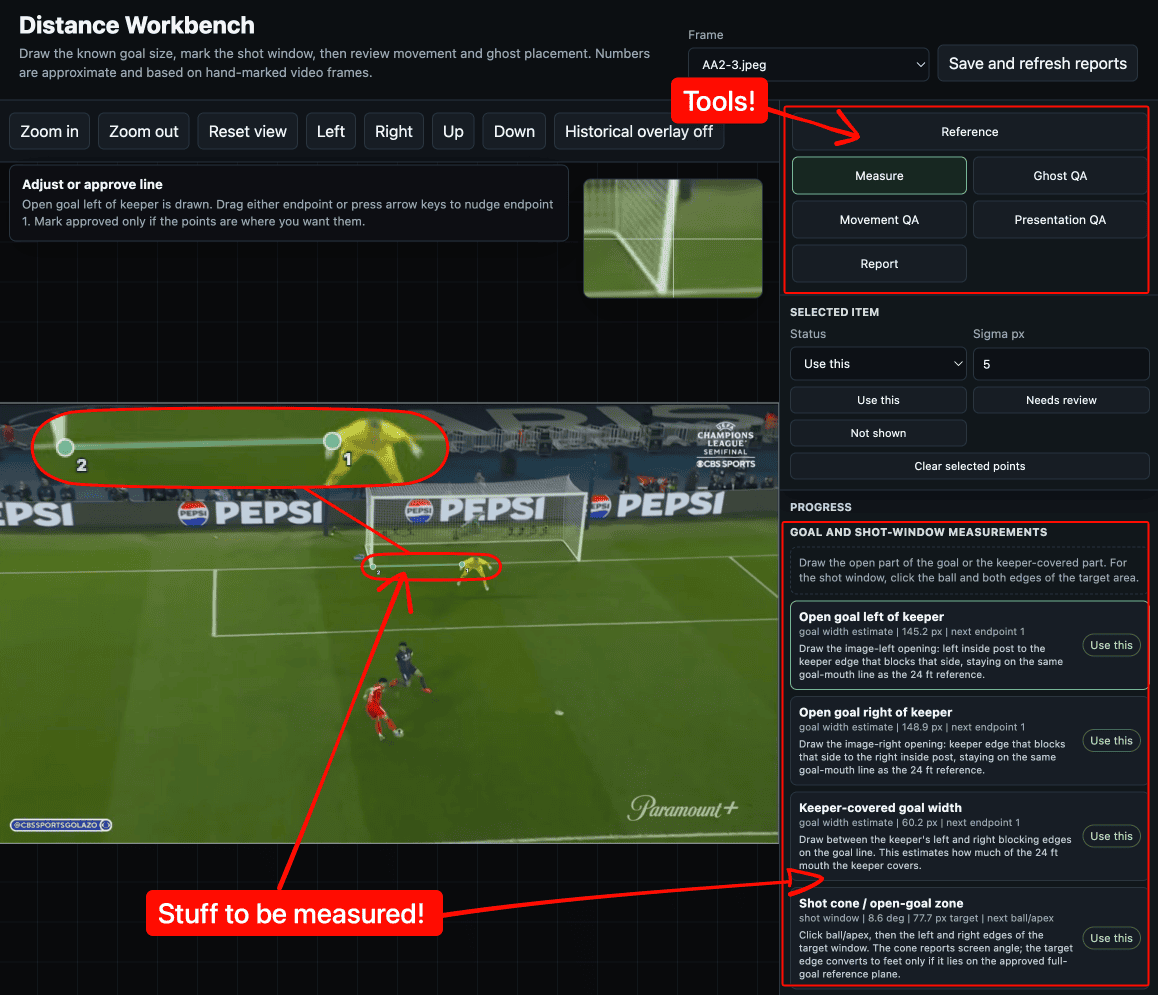
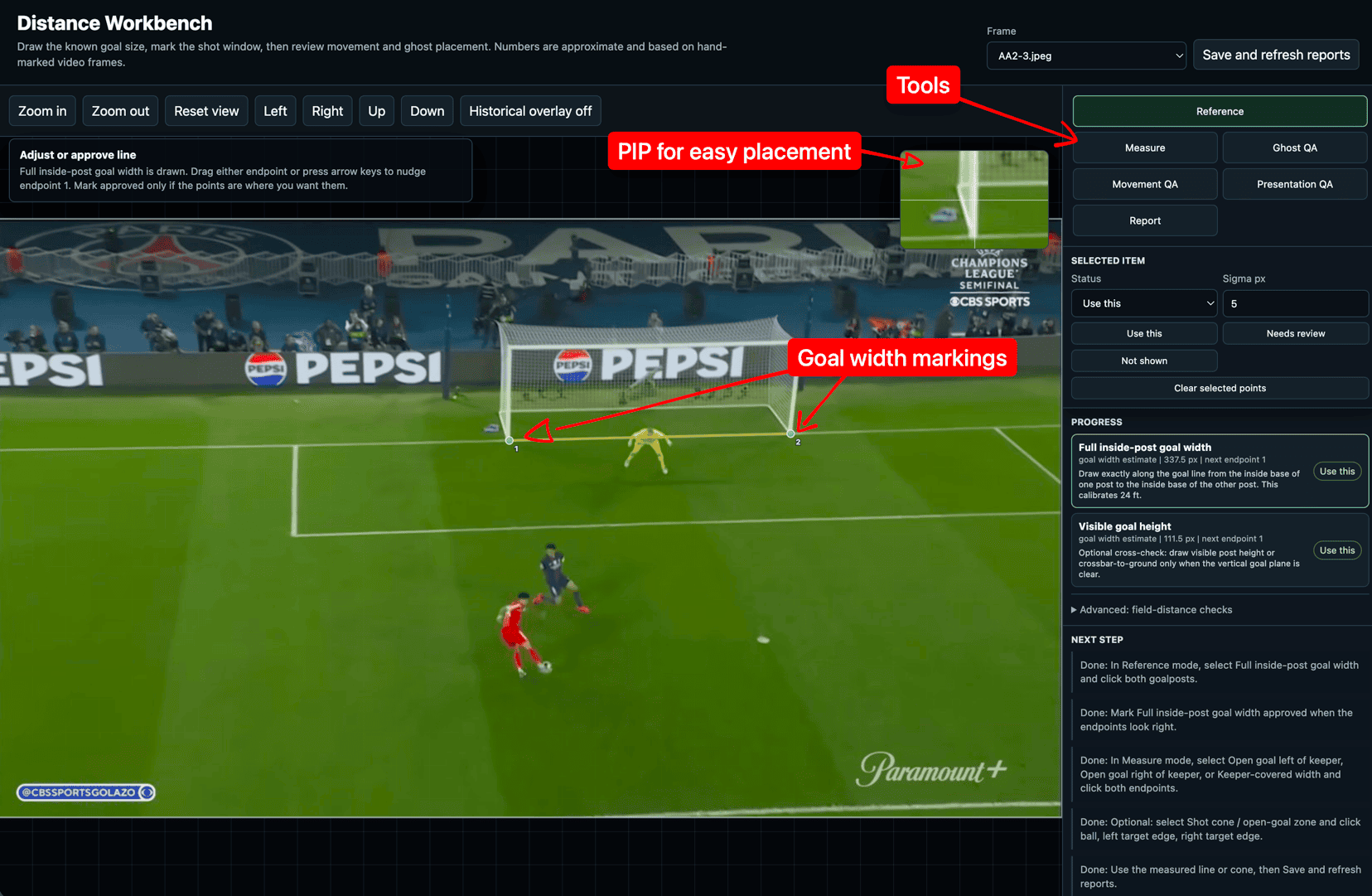
Learning: Codex will happily write more code before it suggests letting you help. You have to ask for the human-in-the-loop pipeline; it will not offer it.
Learning 3: Agents can name what you don’t know to ask
Calculating the player movement was harder. For movement, we needed to compare player foot positions across two different broadcast frames where the camera angle changes slightly. The players move across the pitch which is a flat plane, but the image is perspective-distorted. You cannot just subtract pixel coordinates and call it distance.
I described the perspective problem to Codex and it came back with “homography” which is a word I had never heard of before. In simple terms, homography lets you map points from one view of a flat surface to another view of that same surface. In this case, the flat surface is the football pitch. We could apply this concept to this use-case because in our case the pitch is the same planar surface between these two frames and the players feet represent same points on that plane.
This is where the collaboration got interesting. I steered the measurement process using domain intuition. I knew which points mattered as well as when a foot marker felt wrong. I knew that same-foot movement was a better metric than mixing left and right foot positions. Codex did the engineering work. It wrote the workbench server, the UI, the JSON review files, the geometry helpers, the tests, and the final HTML generator. As I saw the benefits of our initial collaboration, I kept getting ambitious and asking more and more of Codex. We kept building: a goal measurement tool, a movement tracker, a ghost alignment layer, and a final QA tool for placing labels directly on the shareable image.
Here’s what it ended up looking like and it was glorious!
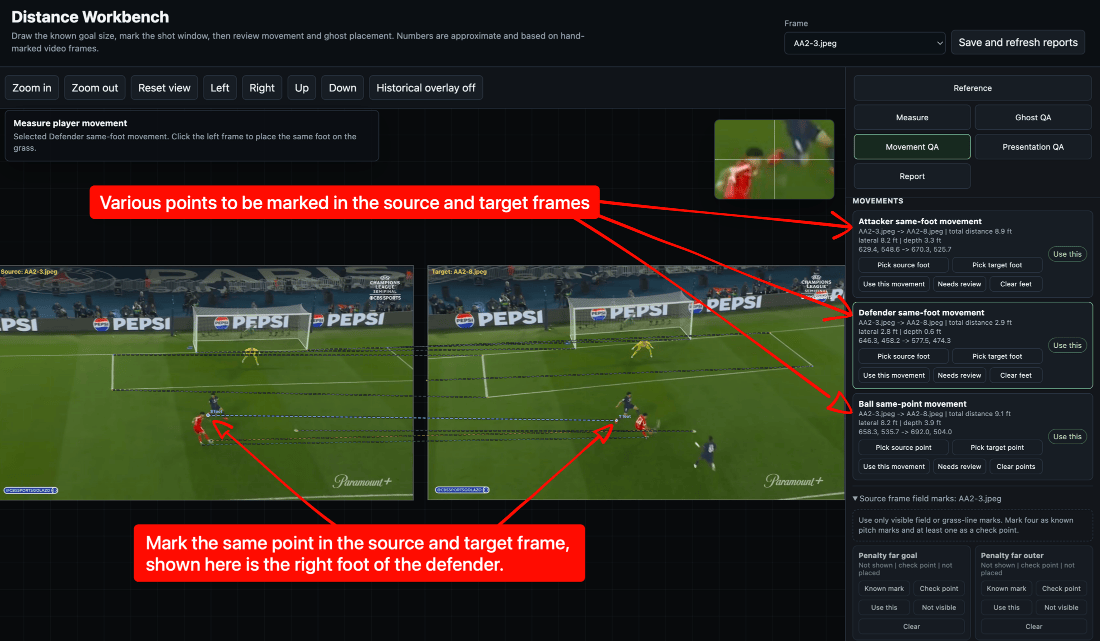
Learning: Don’t be afraid to be ambitious! What AI can accomplish might just surprise you.
Learning 4: Your context unlocks better tools than the agent’s defaults
The final visual still needed to be understandable without reading a measurement report. I had another idea: what if we placed the players from the previous frame into the later frame at low opacity, like ghosts? That would show how far they had moved without relying only on arrows.
Codex first tried to cut out the players using Python. The result was not great. Here are a couple of early examples:
- In the first example, the cutouts are basically ovals around players in the previous frame which also includes the grass from the rest of the frame that frankly just looks like eggs placed in the middle of a frame.
- In the second example, the cutouts were too wide, included too much grass, and did not follow the body outlines closely enough.
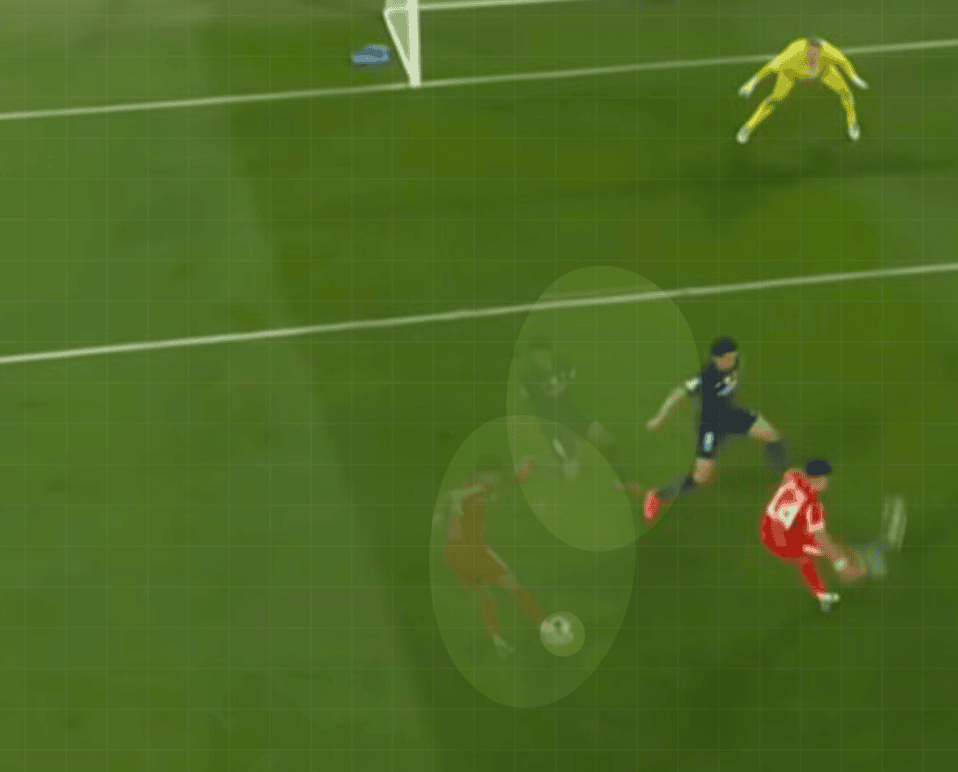
Then I remembered we were on a Mac. Apple has Vision APIs for foreground extraction and segmentation. Out of curiosity, I asked Codex if we could use Apple Neural Engine (ANE) for this problem. Although the solution Codex came up with didn’t leverage ANE, Codex’s suggested Apple Vision APIs gave me a much better cutout as seen below.

The cutout script used Apple Vision’s VNGenerateForegroundInstanceMaskRequest to generate a foreground mask. The resulting player cutouts were much tighter around the bodies than the earlier Python attempt. I do not know whether this is the same underlying API Apple uses for iPhone camera app portrait mode but visually it felt like the right class of tool.
I then used the ghost alignment tool in the workbench to place the previous-frame cutout into the later frame.
When the ghost finally sat inside the later frame at the right scale, in the right position, and pointing the right direction, it was a pure Michael Scott happy moment for me. That was the instant the whole project felt real.

Learning: Codex reached for Python tools because those are its safe defaults. Only because I asked about MacOS APIs did it try the Apple Vision APIs, which produced much cleaner cutouts. The agent will not ask what hardware or ecosystem you have. You have to offer that context yourself.
Conclusion
Yes, professional tracking systems exist. This exercise was never about building a better one. It was about seeing how far a curious non-engineer could get with just an agent and some domain knowledge.
My biggest learning from this exercise is that when I use AI in a domain I know well, I can push back. I can tell when something feels wrong and I can add missing context. My football intuition caught things that Codex did not know to care about.
But when I use AI in a domain I do not know, what am I failing to ask for? What assumptions am I accepting because the output looks polished/correct? What useful result am I leaving on the table because my prompt does not contain the domain nuance?
The most important lesson I learned was not that AI should replace human judgement but that AI gets much more useful when human judgement has a place to go.